문자열 속성과 바이너리 속성의 차이점
문자열 속성은 문자열에 포함된 NULL 문자 0을 찾아서 데이터 크기를 체크하기 때문에 문자열 길이를 추가로 적을 필요가 없다. 예를 들어 "abc" 문자열이 있으면 a, b, c 다음에 NULL 문자인 0이 있으므로 문자열을 체크하여 데이터 크기가 3이라는 것을 알 수 있다. 하지만 바이너리 속성은 데이터를 그냥 숫자로만 판단하기 때문에 표준 입출력 함수가 데이터를 분석해서 길이나 크기를 알아낼 수 없다. 따라서 바이너리 속성으로 데이터를 읽거나 쓰려면 반드시 프로그래머가 직접 크기를 적어주어야 한다. 이런 특성은 바이너르 속성을 사용하는 바이너리 파일에서도 마찬가지로 적용된다. 따라서 바이너리와 관련된 파일 입출력 함수는 대부분 데이터 크기를 적도록 되어 있다.
바이너리 파일에 데이터 저장하기 : fwrite 함수
fwrite 함수는 다음과 같은 형식으로 호출해서 데이터를 저장한다.
| 함수 원형: size_t fwrite(const void *buffer, size_t_size, size_t count, FILE *stream); 사용 형식: frite(저장할 데이터의 시작 주소, 저장할 데이터의 기준 단위 크기, 반복 횟수, 파일 포인터) |
예를 들어 int형 변수 data에 저장되어 있는 16진수 값을 파일에 저장하고 싶다면 다음과 같이 코드를 구성하면 된다.
| int data = 0x00000412; /*data 변수가 할당된 메모리를 4바이트 크기만큼 1회만 p_file 포인터가 가리키는 파일에 저장함*/ fwrite(&data, sizeof(int), 1, p_file); |
이렇게 fwrite를 사용하면 p_file 파일 포인터가 가리키는 바이너리 파일에 data 변수의 값이 4바이트 크기로 복사된다.
fwrite 함수는 저장할 데이터의 시작 주소부터 데이터의 기준 단위 크기로 반복 횟수만큼 파일에 데이터를 쓰게 된다. 따라서 실제로 파일에 저장되는 크기는 '기준 단위 크기 X 반복 횟수'이다. 따라서 앞의 예시에서 4바이트가 저장된 이유는 fwrite 함수를 호출할 때 사용한 두 번째와 세 번째 매개변수를 곱한 크기만큼 데이터가 저장되기 때문이다. 즉 데이터가 sizeof(int) x 1 크기로 저장된다.
fwrite 함수를 사용해서 바이너리 파일에 int형으로 만든 변수의 값을 저장하는 예제를 만들어 보자. 다음은 jin.dat 파일을 바이너리 속성으로 열어서 data 변수에 0x00000412 값을 저장하는 예제이다.

위의 예제를 실행했을 때 소스 파일이 있는 경로에 zzzzz.dat 파일이 없다면 파일이 새로 만들어지고, zzzzz.dat 파일이 있다면 내용이 전부 지워진 채로 열릴 것이다. 하지만 이 파일이 바이너리 파일이기 때문에 0x0412 값이 제대로 저장되었는지 확인하기 어렵다.
fwrite 함수의 세 번째 배개변수 '반복 횟수'의 용도
fwrite 함수를 사용하여 int 형 배열의 내용을 파일에 저장하고 싶다면 다음과 같이 사용한다.
| int data[5] = {0, 1, 2, 3, 4}; /*data 배열의 시작 주소부터 4바이트 단위로 5회 반복해서 파일에 저장함*/ fwrite(data, sizeof(int), 5, p_file); |
앞의 예제에서 배열로 선언한 data 변수는 int 크기의 변수 5개를 의미한다. 따라서 fwrite 함수를 사용할 때 두 번째 매개변수에는 int형 크기를 적고, 세 번째 매개변수에는 5번 반복을 의미하는 값 5를 적었다. 하지만 fwrite 함수를 사용해서 배열을 저장한다고 해서 저장할 크기를 반드시 '단위 크기'와 '반복 횟수'로 나누어야 하는 것은 아니다. 다음과 같이 사용하는 경우가 더 많다.
| fwrite(data, sizeof(int) * 5, 1, p_file); |
단위 크기를 sizeof(int), 반복 횟수를 5라고 적은 경우는 배열 요소에 의미를 더 부여한 것이고, 단위 크기를 sizeof(int)x5, 반복 횟수를 1이라고 적은것은 20바이트 메모리라는 것을 더 강조하는 형태이다. 그렇지 않고 배열의 크기를 사용해서 다음과 같이 적기도 한다. sizeof(data)를 사용하면 data 배열의 크기를 의미하기 때문에 20으로 번역된다.
| fwrite(data, sizeof(data), 1, p_file); |
fwrite 함수를 사용해서 데이터를 저장하면 파일 포인터가 가리키는 정보중에서 '파일 내부 데이터를 읽거나 쓰기 시작하는 위치'가 데이터를 저장한(단위크기x횟수) 크기만큼 자동으로 증가한다.
fwrite 함수를 사용해서 데이터를 저장하면 파일 포인터가 가리키는 정보중에서 '파일 내부 데이터를 읽거나 쓰기 시작하는 위치'가 데이터를 저장한(단위크기x횟수) 크기만큼 자동으로 증가한다. 따라서 파일에 데이터를 저장한 만큼 이동하는 함수를 추가로 사용할 필요가 없다. 즉 현재 열어놓은 파일의 내부 위치를 이동시키는 작업을 하지 않고 나열식으로 fwrite 함수를 사용하더라도 같은 위치에 계속 데이터를 덮어쓰지 않고 순차적으로 저장된다.
예를 들어 다음 예제처럼 나열식으로 fwrite 함수를 사용하면 바이너리 파일에는 4바이트 크기로 100 값이 저장되고 그 다음 위치에 20바이트 만큼 0, 1, 2, 3, 4값이 저장된다.

| zzzzz.dat | |||||
| 100 -> | 0 -> | 1 -> | 2 -> | 3 -> | 4 -> |
위 표처럼 초록색 화살표가 파일 안에서 쓰기 작업을 할 위치를 표시한 것인데, fwrite 함수가 호출될 때마다 이 위치가 자동으로 이동해서 파일 안에 데이터를 쓴다는 뜻이다.
바이너리 파일에서 데이터 읽기 : fread 함수
바이너리 파일에서 데이터를 읽을 때에는 fread 함수를 사용하여 다음처럼 호출한다.
| 함수 원형 : size_t fread(void *buffer, size_t size, size_t count, FILE *stream); 사용 형식 : fread(읽은 데이터를 저장할 주소, 저장할 데이터의 기준 단위 크기, 반복 횟수, 파일 포인터); |
예를 들어 파일에 저장되어 있는 데이터를 읽어서 int형 변수 data에 저장하고 싶다면 다음과 같이 코드를 구성하면 된다.
| int data; /*p_file이 가리키는 파일에서 4바이트 크기만큼 1회만 데이터를 읽어 와서 data변수에 저장함*/ |
이렇게 fread 함수를 사용하면 p_file 파일 포인터가 가리키는 바이너리 파일에서 4바이트 크기로 데이터를 읽어서 data 변수에 저장한다.
fread 함수를 다시 한 번 정리해 보면 파일에서 기준 단위 크기로 반복 횟수만큼 데이터를 읽어 와서 '데이터를 저장할 주소'에 읽은 데이터를 저장한다. 따라서 실제로 파일에서 읽은 데이터의 크기는 '단위 크기 x 반복 횟수'이다. 위의 예시에서 4바이트를 파일에서 읽은 이유는 fread 함수를 초훌할 때 사용한 두 번째 매개변수와 세 번째 매개 변수를 곱한 크기만큼 읽어 오기 때문이다. 즉 sizeof(int) x 1 크기만큼 읽는다.
fread 함수를 사용해 바이너리 파일의 첫 4바이트를 읽어 와서 int형으로 만든 변수에 값을 저장하는 예제를 만들어 보자. 다음은 zzzzz.dat 파일에 있는 첫 4바이트 데이터를 읽어와서 data 변수에 저장하는 예제이다. 이 예제에서 zzzzz.dat파일을 제대로 읽기 위해서는 소스 파일이 저장된 경로에 zzzzz.dat 파일을 복사해야 한다.

fread 함수를 호출하면 실제로 데이터를 읽어 온 크기만큼 '파일 내부 데이터를 읽거나 쓰기 시작하는 위치'가 증가한다. 그 다음 fread 함수를 호출하면 증가한 위치에서부터 파일 읽기를 시작한다. 따라서 fread 함수도 특별한 위치 지정 없이 파일에서 데이터를 순차적으로 읽어 올 수 있다.
fread 함수의 세 번째 매개변수 '반복 횟수'의 용도
fread 함수를 사용하여 파일에서 20바이트의 데이터를 읽어 와서 int형 배열에 저장하고 싶다면 다음과 같이 코드를 구성하면 된다.
| int data[5]; /*파일에서 4바이트 단위로 5회 반복해서 데이터를 읽어와 data 배열에 저장함*/ fread(data, sizeof(int), 5, p_file); |
배열로 선언한 data 변수는 int 크기의 변수 5개를 의미한다. 따라서 fread 함수를 사용할 때 두 번째 매개변수에는 int형의 크기를, 세 번째 매개 변수에는 5회 반복을 의미하는 값 5를 적었다. 하지만 fread 함수가 배열을 사용한다고 해서 읽어 올 전체 데이터 크기를 반드시 '단위 크기' 와 '반복횟수'로 나누어야 하는것은 아니다. 사실 다음과 같이 사용하는 경우가 더 많다.
| fread(data, sizeof(int)*5, 1, p_file); |
단위 크기를 sizeof(int)라고 적은 경우는 배열 요소에 의미를 더 부여한 것이고, 앞 예제처럼 sizeof(int)*5라고 적은 것은 전체 데이터 크기가 20바이트 메모리라는 것을 더 강조하는 형태이다. 아니면 배열의 크기를 사용해서 다음과 같이 적기도 한다. sizeof(data)라고 사용하면 data 배열의 크기를 의미하기 때문에 값 20으로 번역한다.
| fread(data, sizeof(data), 1, p_file); |
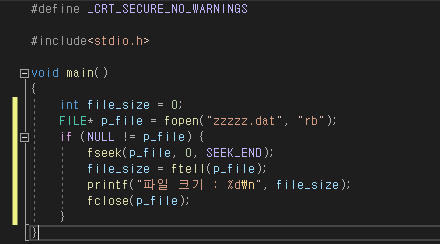
파일 내부의 작업 위치 탐색하고 확인하기 : fseek, ftell 함수
파일에 저장된 데이터를 꼭 순차적으로 읽을 필요는 없다. 필요에 따라 fseek 함수를 사용하여 원하는 위치로 건너 뛰거나, 읽은 위치로 돌아가서 읽었던 데이터를 다시 읽을 수도 있다. fseek 함수는 다음과 같은 형식으로 호출된다.
| 함수 원형 : int fseek(FILE *stream, long offset, int origin) |
이 함수는 파일의 데이터를 읽을 기준 위치로 SEEK_SET(파일의 시작), SEEK_END(파일의 끝), SEEK_CUR(현재 위치)를 사용할 수 있고 지정한 기준 위치로 부터 사용자가 지정한 '이동 거리'만큼 이동한다. 이동거리는 양수 또는 음수로 지정할 수 있으며 양수를 명시하면 지정한 기준 위치에서 뒤로 이동하며 음수를 명시하면 앞으로 이동한다. 그리고 실제로 이동한 위치는 파일 포인터에 저장된다. fseek 함수를 사용하는 예시 코드는 다음과 같다.
| fseek(p_file, 0 , SEEK_SET); /*파일 시작 위치로 이동함*/ |
| fseek(p_file, 32, SEEK_CUR); /*현재 위치에서 32바이트 만큼 뒤로 이동함*/ |
이렇게 이동한 위치를 값으로 확인하고 싶으면 ftell 함수를 사용하면 된다. ftell 함수가 반환하는 값은 시작 위치를 0으로 계산한 값이기 때문에 파일의 끝으로 이동한 후에 ftell 함수를 사용하면 파일의 전체 크기를 알아낼 수도 있다.
| 함수 원형 : long ftell(FILE *stream); 함수 사용 형식 : 현재 열려 있는 파일 내에서 데이터를 읽거나 저장할 위치 = ftell(파일 포인터); |
'C언어' 카테고리의 다른 글
| 17) 함수 포인터 (0) | 2022.02.03 |
|---|---|
| 16-1) 파일 열기와 닫기 (0) | 2021.12.30 |
| 16)파일 입출력 (0) | 2021.11.15 |
| 15-3) 구조체를 활용한 연결 리스트 (0) | 2021.10.15 |
| 15-2)구조체로 만든 자료형의 크기 (0) | 2021.10.05 |